Introduction
Do you want to extract text from an image or pdf? Well great, as of the v0.2.3 release you can! (Though keep in mind its only in Alpha at the moment)
Gowall supports a lot of providers Local/Selfhosted & Cloud based both LLM-OCR based and traditional OCR based, or even a mix of both (think ocr with tesseract and correct grammar and other mistakes with llms either cloud or selfhosted). As always i like to give everyone all the choices possible, the choice is up to you.
This introduction section will cover all the concepts you need to understand and you can click in the links for more details.
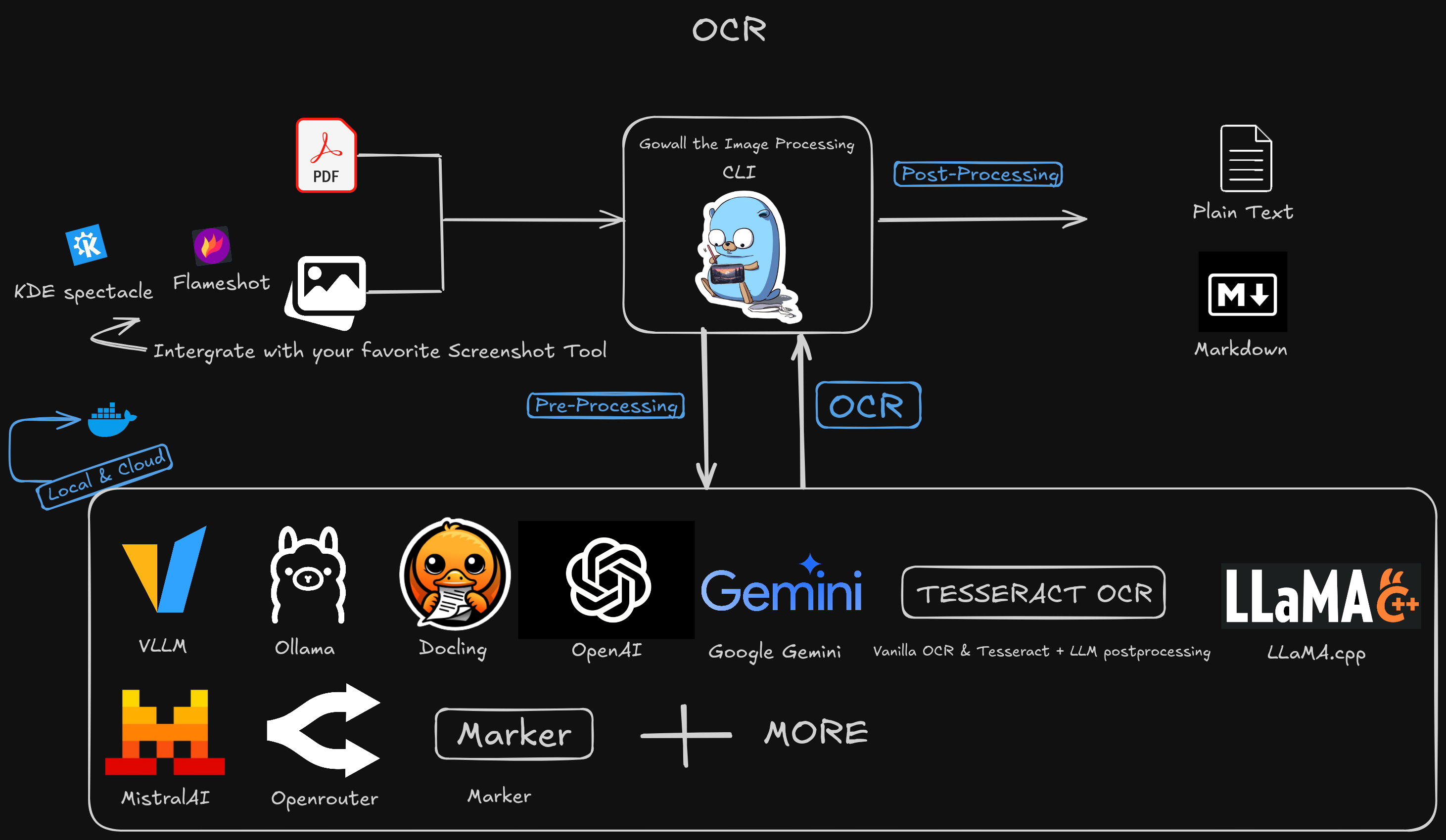
Make sure to read the following concepts you will need to understand them before using the ocr feature.
Providers
Let's start with the list of providers gowall supports, Personally i use both local and cloud based providers depending on the task at hand.
Where i would use cloud based providers
If i want OCR an image (like past exams to discuss the answers with llms without having a limit like 4 uploads/daily like all chatbot sites have) i would use cloud base providers for free,fast and accurate OCR.
Where i would use local/selfhosted providers
If i want to OCR something like a receipt or a pdf containing very sensitive info like blood tests etc.. to insert them in my vault, i would use local/selfhosted providers for privacy and security.
Local/SelfHosted
Not-LLM OCR based
- Tesseract see the gowall tesseract guide here
- Docling see the gowall Docling guide here (docling has both choices that's why it appears in 2 sections)
LLM-OCR based
- VLLM see the gowall VLLM guide here
- Ollama see the gowall Ollama guide here
- Docling see the gowall Docling guide here
- OC every OpenAI compatible API endpoint (selfhosted or not), see the gowall OC guide here
Cloud based
- OpenAI see the gowall OpenAI guide here
- OpenRouter see the gowall OpenRouter guide here
- Gemini see the gowall Gemini guide here
- Mistral see the gowall Mistral guide here
One Interface & Schemas
Just as i'm trying to make gowall the one image processing tool to rule them all (get the reference lol?) the same goes for ocr.
To acomplish that gowall provides a single common interface to interact with all the providers. In one moment you can OCR an image with Ollama and the next with Openrouter.
gowall ocr img.png -p openrouter -m qwen/qwen2.5-vl-72b-instruct:free"
gowall ocr img.png -p ollama -m qwen2.5vl:7b
Now this gets repetive doesn't it? the ocr command has a lot of flags (rate limiting, prompt, language etc..) and it would be impossible to specify provider specific options.
Thats why i have created schemas to cut down boilerplate. They are specified in ~/.config/gowall/schema.yml and are options so you don't repeat yourself. You can additionally add them in your dotfiles so they are forever saved.
schemas:
- name: "op-qwen" # <-- the most simplistic schema just for an introduction to the concept
config:
ocr:
provider: "openrouter"
model: "qwen/qwen2.5-vl-72b-instruct:free"
- name: "gem"
config:
ocr:
provider: "gemini"
model: "gemini-2.5-flash"
Now the only thing you need to do is just specify the schema name you want to use. Lets use the newly created op-qwen schema. Clean don't you think?
gowall ocr img.png -s op-qwen
You can obviously overwrite anything with flags. The priority is always flags > schema.yml options.
gowall ocr img.png -s op-qwen -m deepseek/deepseek-chat-v3.1:free
There are a lot more options to add in a schema like configuring rate limiting, replacing/appending prompts, messing with concurrency per stage in pre/post processing ... you get it, i have kept it very very simple here for demonstration purposes. You can check the guide here for more info.
Rate-Limiting
Just because gowall can send a gazillion requests per second to any provider doesn't mean it should. If you are selfhosting something and you let gowall run amok on big files with no rate limits you will see 100% usage and everything will slow to a crawl.If you are using cloud based providers they will simply will rate limit you once you exceed their limits.
Read the Warning? Great. Rate limits is the most imporant thing you need to understand here.
Just because i know some people wont even glance at the docs, to prevent people trying to OCR a 400 page pdf with a selfhosted model on a provider that doesn't supports pdfs (so gowall has to do more work to convert it into images) on a potato laptop that would cause 100% CPU/GPU usage and everything slowing to a crawl,i have specifically manually added some rate limits for gowall and intentionally capping its OCR performance
Adjusting Rate Limits
As mentioned above gowall has some rate limits options by default. You may have better hardware or you may have already paid for a provider like OpenAI and have a lot higher limits. Adjust them to increase performance/reduce time taken
gowall ocr img.png -s op-qwen -r 4 -b 4
Following the token bucket rate limiting algorithm.
➤ -r is the requests per second flag.
➤ -b is the burst requests flag.
Obviously you can set them in your schema.yml file as well.
- name: "op-qwen"
config:
ocr:
provider: "openrouter"
model: "qwen/qwen2.5-vl-72b-instruct:free"
rate_limit:
rps: 4
burst: 4
You should check the rate limiting guide here for more info and examples, this is merely an introduction.
Pre-Processing
When you feed gowall a pdf or an image it does some pre-processing to make it easier for a model to understand or lowering the image size (lower tokens, lower cost).
You can play around with some options, see the pre-processing guide here for more info.
Post-Processing
When the provider OCR's the image/pdf gowall can perform post-processing. Right now there exists only text correction to essentially pair up tesseract with fast OCR and an llm that corrects grammar mistakes, closes brackets etc...
You can play around with some options, see the post-processing guide here for more info.